Mean, Mode, Median, and Standard Deviation
The Mean and Mode
The sample mean is the average and is computed as the sum of all the observed outcomes from the sample divided by the total number of events. We use x as the symbol for the sample mean. In math terms,
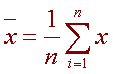
where n is the sample size and the
x correspond to the observed
valued.
Example
Suppose you randomly sampled six acres in the Desolation Wilderness for a non-indigenous weed and came up with the following counts of this weed in this region:
34, 43, 81, 106, 106 and 115
We compute the sample mean by adding and dividing by the number of samples, 6.
34 + 43 + 81 + 106 + 106 + 115
= 80.83
6
We can say that the sample mean of non-indigenous weed is 80.83.
The mode of a set of data is the number with the highest frequency. In the above example 106 is the mode, since it occurs twice and the rest of the outcomes occur only once.
The population mean is the average of the entire population and is usually impossible to compute. We use the Greek letter m for the population mean.
Median, and Trimmed Mean
One problem with using the mean, is that it often does not depict the typical outcome. If there is one outcome that is very far from the rest of the data, then the mean will be strongly affected by this outcome. Such an outcome is called and outlier. An alternative measure is the median. The median is the middle score. If we have an even number of events we take the average of the two middles. The median is better for describing the typical value. It is often used for income and home prices.
Example
Suppose you randomly selected 10 house prices in the South Lake Tahoe area. Your are interested in the typical house price. In $100,000 the prices were
2.7, 2.9, 3.1, 3.4, 3.7, 4.1, 4.3, 4.7, 4.7, 40.8
If we computed the mean, we would say that the average house price is 744,000. Although this number is true, it does not reflect the price for available housing in South Lake Tahoe. A closer look at the data shows that the house valued at 40.8 x $100,000 = $4.08 million skews the data. Instead, we use the median. Since there is an even number of outcomes, we take the average of the middle two
3.7 + 4.1
= 3.9
2
The median house price is $390,000. This better reflects what house shoppers should expect to spend.
There is an alternative value that also is resistant to outliers. This is called the trimmed mean which is the mean after getting rid of the outliers or 5% on the top and 5% on the bottom. We can also use the trimmed mean if we are concerned with outliers skewing the data, however the median is used more often since more people understand it.
Example:
At a ski rental shop data was collected on the number of rentals on each of ten consecutive Saturdays:
44, 50, 38, 96, 42, 47, 40, 39, 46, 50.
To find the sample mean, add them and divide by 10:
44 + 50 + 38 + 96 + 42 + 47 + 40 + 39 + 46 + 50
= 49.2
10
Notice that the mean value is not a value of the sample.
To find the median, first sort the data:
38, 39, 40, 42, 44, 46, 47, 50, 50, 96
Notice that there are two middle numbers 44 and 46. To find the median we take the average of the two.
44 + 46
Median =
= 45
2
Notice also that the mean is larger than all but three of
the data points. The mean is influenced by outliers while the median is
robust.
Variance, Standard Deviation and Coefficient of Variation
The mean, mode, median, and trimmed mean do a nice job in telling where the center of the data set is, but often we are interested in more. For example, a pharmaceutical engineer develops a new drug that regulates iron in the blood. Suppose she finds out that the average sugar content after taking the medication is the optimal level. This does not mean that the drug is effective. There is a possibility that half of the patients have dangerously low sugar content while the other half have dangerously high content. Instead of the drug being an effective regulator, it is a deadly poison. What the pharmacist needs is a measure of how far the data is spread apart. This is what the variance and standard deviation do. First we show the formulas for these measurements. Then we will go through the steps on how to use the formulas.
We define the variance to be
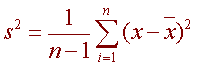
and the standard deviation to be
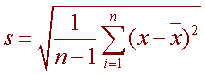
Variance and Standard Deviation: Step by Step
Calculate the mean, x.
Write a table that subtracts the mean from each observed value.
Square each of the differences.
Add this column.
Divide by n -1 where n is the number of items in the sample This is the variance.
To get the standard deviation we take the square root of the variance.
Example
The owner of the Ches Tahoe restaurant is interested in how much people spend at the restaurant. He examines 10 randomly selected receipts for parties of four and writes down the following data.
44, 50, 38, 96, 42, 47, 40, 39, 46, 50
He calculated the mean by adding and dividing by 10 to get
x = 49.2
Below is the table for getting the standard deviation:
| x | x - 49.2 | (x - 49.2 )2 |
|
44 |
-5.2 | 27.04 |
| 50 | 0.8 | 0.64 |
| 38 | 11.2 | 125.44 |
| 96 | 46.8 | 2190.24 |
| 42 | -7.2 | 51.84 |
| 47 | -2.2 | 4.84 |
| 40 | -9.2 | 84.64 |
| 39 | -10.2 | 104.04 |
| 46 | -3.2 | 10.24 |
| 50 | 0.8 | 0.64 |
| Total | 2600.4 |
Now
2600.4
= 288.7
Hence the variance is 289 and the standard deviation is the square root of 289 = 17.
49.2 - 17 = 32.2
What this means is that most of the patrons probably spend between $32.20 and $66.20.
The sample standard deviation will be denoted by s and the population standard deviation will be denoted by the Greek letter s.
The sample variance will be denoted by s2 and the population variance will be denoted by s2.
The variance and standard deviation describe how spread out the data is. If the data all lies close to the mean, then the standard deviation will be small, while if the data is spread out over a large range of values, s will be large. Having outliers will increase the standard deviation.
One of the flaws involved with the standard deviation, is that it depends on the units that are used. One way of handling this difficulty, is called the coefficient of variation which is the standard deviation divided by the mean times 100%
s
CV =
100%
m
In the above example, it is
17
100% = 34.6%
49.2
This tells us that the standard deviation of the restaurant bills is 34.6% of the mean.
Chebyshev's Theorem
A mathematician named Chebyshev came up with bounds on how much of the data must lie close to the mean. In particular for any positive k, the proportion of the data that lies within k standard deviations of the mean is at least
1
1 -
k2
For example, if k = 2 this number is
1
1 -
= .75
22
This tell us that at least 75% of the data lies within 75% of the mean. In the above example, we can say that at least 75% of the diners spent between
49.2 - 2(17) = 15.2
and
49.2 + 2(17) = 83.2
dollars.
Back to the Descriptive Statistics Home Page
Back to the Elementary Statistics (Math 201) Home Page